Arduino
Microcontroller FFT & IFFT Performance Benchmark (N=64)
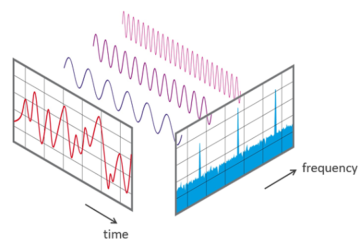
The Fast Fourier Transform (FFT) is an efficient algorithm for computing the Discrete Fourier Transform (DFT): it converts a signal from the time domain into the frequency domain, revealing which frequencies are present in a signal and how strong they are. It is the workhorse behind spectrum analyzers, audio effects, filtering, and countless other DSP applications. I recently published a new FFT library that supports both integer and floating-point data types for its calculations. Using Read more